INTRODUCCIÓN A BASE DE DATOS, SQL Y POSTGRESQL. TEOREMA DE CAP
¿Qué son los Datos?
Los datos son la unidad mínima de información, representando hechos, conceptos o instrucciones en un formato estructurado para su interpretación, procesamiento o transmisión. Son símbolos que por sí solos pueden no tener un significado claro, pero que al ser procesados y contextualizados se convierten en información valiosa.
De Datos a Información
La relación entre datos e información es fundamental:
- Dato: Es un valor único y aislado (por ejemplo: “25”, “Juan”, “Madrid”).
- Información: Es el resultado de procesar, organizar y contextualizar conjuntos de datos relacionados (por ejemplo: “Juan tiene 25 años y vive en Madrid”).
En el contexto de las bases de datos, los datos son la materia prima que almacenamos, organizamos y gestionamos para transformarlos en información útil y significativa.
Características de los Datos
Los datos pueden clasificarse según su estructura y organización:
1. Datos Estructurados
Son datos altamente organizados con un formato definido y esquema fijo. Son fáciles de almacenar, consultar y analizar.
Ejemplos:
- Tablas de bases de datos relacionales (filas y columnas)
- Hojas de cálculo Excel con columnas definidas
- Datos de formularios web estructurados
- Registros de transacciones bancarias
2. Datos No Estructurados
Carecen de un formato predefinido y no se ajustan a un modelo de datos específico. Representan la mayoría de los datos en el mundo digital.
Ejemplos:
- Documentos de texto (Word, PDF, TXT)
- Correos electrónicos
- Publicaciones en redes sociales
- Archivos multimedia (fotos, videos, audio)
- Datos de sensores IoT
Ejemplo de datos no estructurados:
Estimado equipo,
La reunión de hoy se ha pospuesto para mañana a las 15:00.
Saludos,
Juan Pérez3. Datos Semi-estructurados
No tienen una estructura tan rígida como los estructurados, pero contienen etiquetas o marcadores que separan diferentes elementos.
Ejemplos:
- Archivos JSON y XML
- Hojas de cálculo con celdas combinadas
- Correos electrónicos con metadatos estructurados
- Datos de sensores con marcas de tiempo
Ejemplo en JSON:
{
"empleado": {
"id": 101,
"nombre": "Ana García",
"proyectos": ["PostgreSQL", "API REST"],
"activo": true,
"fecha_ingreso": "2023-01-15"
}
}Ejemplo en XML:
<empleado>
<id>101</id>
<nombre>Ana García</nombre>
<proyectos>
<proyecto>PostgreSQL</proyecto>
<proyecto>API REST</proyecto>
</proyectos>
<activo>true</activo>
<fecha_ingreso>2023-01-15</fecha_ingreso>
</empleado>¿Qué es una Base de Datos?
Una base de datos es un sistema organizado que almacena información de manera estructurada, permitiendo guardar, consultar y gestionar datos de forma eficiente. Es como un gran archivador digital, pero mucho más potente y seguro.
¿Por qué son esenciales? Las bases de datos permiten:
- Almacenar grandes volúmenes de información sin perder orden.
- Recuperar datos al instante, incluso entre millones de registros.
- Garantizar que la información sea precisa y consistente (evitando duplicados o errores).
- Manejar múltiples usuarios al mismo tiempo sin corromper los datos.
- Proteger la información con permisos y cifrado contra accesos no autorizados.
Los datos: El activo más valioso
Si el software de una empresa falla, puede reinstalarse. Si un servidor se daña, puede reemplazarse. Pero si se pierden los datos, no hay vuelta atrás. Por eso, las bases de datos son el corazón de toda organización moderna; sin ellas, las empresas no podrían operar, tomar decisiones ni servir a sus clientes de manera eficiente.
Breve Historia de las Bases de Datos
Años 60: Los inicios
Todo comenzó en la década de 1960, cuando aparecieron los primeros sistemas de gestión de bases de datos (DBMS). En esa época, dominaban los modelos jerárquico y de red, con sistemas como IMS de IBM, diseñados para manejar grandes volúmenes de datos en entornos empresariales.
Años 70: La revolución relacional
En 1970, Edgar F. Codd cambió todo al proponer el modelo relacional, una forma más flexible y eficiente de organizar los datos. Esto llevó al desarrollo del lenguaje SQL (Structured Query Language) y a los primeros sistemas relacionales, como System R e Ingres, que sentaron las bases de lo que usaríamos décadas después.
Años 80: La consolidación
Los sistemas relacionales se popularizaron, y empresas como Oracle, IBM (DB2) y Microsoft (SQL Server) se convirtieron en líderes del mercado. Además, se estandarizó el lenguaje SQL, permitiendo mayor compatibilidad entre sistemas.
Años 90-2000: Expansión y diversificación
Con el auge de internet, las bases de datos evolucionaron para soportar aplicaciones web. Surgieron alternativas como MySQL (rápido y open-source) y PostgreSQL (más avanzado y extensible). También aparecieron las primeras bases de datos orientadas a objetos, aunque el modelo relacional siguió dominando.
2010-Actualidad: La era del Big Data y la nube
Hoy, las bases de datos no solo son relacionales. El crecimiento del Big Data impulsó los sistemas NoSQL (como MongoDB y Cassandra), diseñados para escalar horizontalmente. Además, la computación en la nube permitió servicios gestionados como Amazon RDS, Google Cloud SQL y Azure Database.
Tipos de Bases de Datos
1. Relacionales (SQL)
Las bases de datos SQL (Structured Query Language) son sistemas diseñados para almacenar y gestionar información de manera estructurada. A diferencia de otros modelos, organizan los datos en tablas relacionadas (de ahí su nombre de “bases de datos relacionales”), donde cada tabla funciona como una cuadrícula ordenada de filas y columnas.
¿Te imaginas una hoja de cálculo? ¡Es similar!
Podríamos comparar una base de datos SQL con Excel
- Las tablas serían como las hojas de cálculo
- Las filas representarían registros individuales (como un cliente o producto)
- Las columnas serían los atributos o características (nombre, precio, fecha, etc.)
Un ejemplo podría ser la siguiente tabla de usuarios:
| id_usuario | nombre | apellido | edad | ciudad | fecha_registro | suscrito | puntos | |
|---|---|---|---|---|---|---|---|---|
| 1 | Ana | Martínez | ana.martinez@email.com | 28 | Madrid | 2024-01-15 | Sí | 1,250 |
| 2 | Carlos | López | c.lopez@email.com | 34 | Barcelona | 2023-11-22 | No | 850 |
| 3 | María | García | maria.garcia@email.com | 42 | Valencia | 2024-02-03 | Sí | 2,100 |
| 4 | Juan | Rodríguez | j.rodriguez@email.com | 25 | Sevilla | 2024-03-10 | Sí | 500 |
| 5 | Laura | Sánchez | laura.sanchez@email.com | 31 | Málaga | 2023-12-05 | No | 1,750 |
Esta tabla guarda información sobre los usuarios de un juego, como su nombre, apellido, email, edad, ciudad, fecha de registro, si está suscrito y sus puntos. Cuando abordemos más a detalle las bases de datos SQL, profundizaremos en el concepto de tablas y su estructura.
NoSQL
Las bases de datos NoSQL (No Solo SQL) son sistemas de almacenamiento de datos diseñados para manejar grandes volúmenes de información no estructurada o semiestructurada, a diferencia de las bases de datos relacionales tradicionales (SQL), que usan tablas con esquemas fijos como el que vimos con la tabla de arriba.
La forma en que se almacenan los datos puede variar según la naturaleza o el tipo de la base de datos:
En Memoria
Las bases de datos en memoria son sistemas de almacenamiento de datos NoSQL que almacenan datos en la memoria RAM para proporcionar acceso rápido y eficiente a los datos. Son ideales para aplicaciones que requieren acceso rápido a los datos, como aplicaciones web y aplicaciones móviles: Redis, Memcached
Este tipo de base de datos es ideal para aplicaciones que requieren acceso inmediato a los datos. Por ejemplo, Redis es capaz de acceder a altos volúmenes de datos con latencias de menos de un milisegundo. Sin embargo, su estructura de guardado y procesamiento de los datos es muy limitada, por lo que sus aplicaciones son muy específicas. Por ejemplo, el manejo de caché en servidores web.
Documentales
Las bases de datos documentales son sistemas de almacenamiento de datos que almacenan datos de una forma más flexible mediante documentos, como JSON o XML. Por ejemplo, MongoDB. En este la información se guarda en formato JSON:
{
"id": 1,
"nombre": "Ana",
"pedidos": ["Laptop", "Mouse"]
}
Grafos
Son bases de datos NoSQL diseñadas para almacenar y gestionar datos interconectados mediante nodos (entidades) y aristas (relaciones), donde tanto nodos como aristas pueden tener propiedades.
- Ejemplos: Neo4j, ArangoDB
- Especialización: Datos temporales con marcas de tiempo.
- Uso: IoT (Internet de las Cosas), métricas, análisis temporal.
El Teorema CAP en Bases de Datos
El Teorema CAP, propuesto por Eric Brewer en el año 2000, es un principio fundamental en el diseño de sistemas distribuidos, incluyendo bases de datos distribuidas. Este teorema establece que es imposible para un sistema de cómputo distribuido garantizar simultáneamente las siguientes tres propiedades:
-
Consistencia (Consistency)
- Todos los nodos ven los mismos datos al mismo tiempo.
- Cuando se escribe un dato, todas las lecturas posteriores de cualquier nodo devolverán ese valor.
- En el caso de una base de datos, esto significa que si escribimos un nuevo dato en la tabla de la base de datos, las siguientes lecturas de esta tabla devolverán ese nuevo registro que insertamos.
-
Disponibilidad (Availability)
- Todas las solicitudes reciben una respuesta, incluso si algunos nodos están caídos.
- No hay garantía de que sea la versión más reciente de los datos.
- En el caso de una base de datos, significa que siempre obtendremos un valor, incluso si uno de los sistemas está caído.
-
Tolerancia a particiones (Partition tolerance)
- El sistema continúa funcionando a pesar de fallos en la red que dividan a los nodos en grupos aislados.
- En el caso de una base de datos, significa que el sistema podrá continuar funcionando a pesar de fallos en la red que dividan a los nodos en grupos aislados. Es decir, si hacemos una operación y ocurre un fallo en el proceso, la operación no se verá afectada por lo mismo.
En la imagen siguiente se muestra cómo se suele representar el teorema CAP gráficamente, donde cada círculo es una de las propiedades del teorema, y en las intersecciones de estos, podemos ver las combinaciones posibles y qué propiedades cumple cada base de datos.
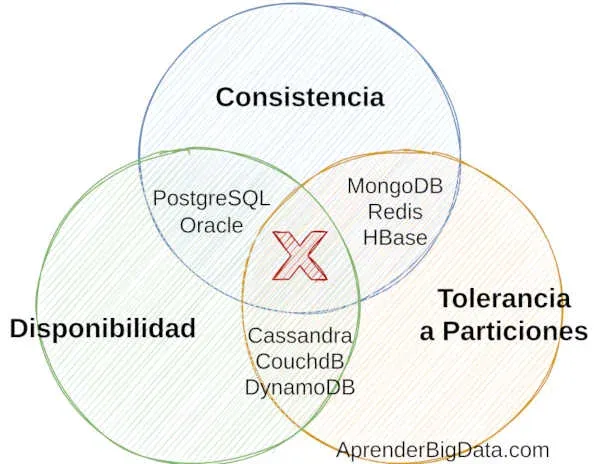
Como se mencionó al inicio, cada tipo de base de datos solo puede cumplir con dos de las tres propiedades al mismo tiempo. Por lo que es importante entender que cada base de datos tiene sus propias limitaciones y ventajas, y que es crucial comprender estas limitaciones a la hora de escoger una base de datos.
Las Tres Combinaciones Posibles
En la práctica, las bases de datos solo pueden garantizar dos de estas tres propiedades al mismo tiempo:
-
CP (Consistencia y Tolerancia a particiones)
- Ejemplo: Bases de datos como MongoDB (en configuración por defecto), HBase
- El sistema mantiene la consistencia y tolerancia a particiones, pero puede no estar disponible durante fallos en la red.
-
AP (Disponibilidad y Tolerancia a particiones)
- Ejemplo: Cassandra, DynamoDB
- El sistema permanece disponible y tolerante a particiones, pero puede devolver datos inconsistentes durante particiones de red.
-
CA (Consistencia y Disponibilidad)
- Ejemplo: Bases de datos relacionales tradicionales como PostgreSQL (en configuraciones estándar)
- Solo es posible en sistemas que no requieren particionamiento, típicamente en una sola ubicación geográfica.
Para comprender esto mejor, consideremos el siguiente ejemplo usando la base de datos de un banco:
Consistencia: en el sector bancario la consistencia es crucial, ya que si un cliente intenta hacer una transacción a otra cuenta por un monto de 1000 dólares, el sistema debe garantizar que el saldo de la cuenta de origen sea igual a 1000 dólares. De lo contrario, esto traería problemas al banco, porque se perdería dinero del cliente o a la cuenta de destino se le depositaría más de lo disponible
Disponibilidad: en el sector bancario la disponibilidad es crucial, ya que un cliente siempre debe tener la capacidad de obtener la información de su cuenta. Usar una base de datos que no esté siempre disponible no le permitirá a los clientes ni al banco obtener la información de las cuentas en todo momento.
Tolerancia a particiones: en el sector bancario la tolerancia a particiones no se cumple. Esto significa que, ante un fallo en el sistema, el banco prefiere cancelar una transacción antes que permitir inconsistencias. Por ejemplo, si un cliente intenta transferir $1000 a otra cuenta y ocurre un error que impide su procesamiento correcto, el sistema revertirá la operación automáticamente. De esta manera:
-
El saldo del cliente no se verá afectado incorrectamente.
-
Se garantiza que no haya discrepancias entre las cuentas involucradas.
-
La operación solo se completará cuando el sistema pueda asegurar su consistencia.
Este enfoque asegura que, incluso en escenarios de fallos técnicos, los datos financieros siempre sean precisos y confiables, evitando riesgos como duplicación de transacciones o saldos incorrectos.
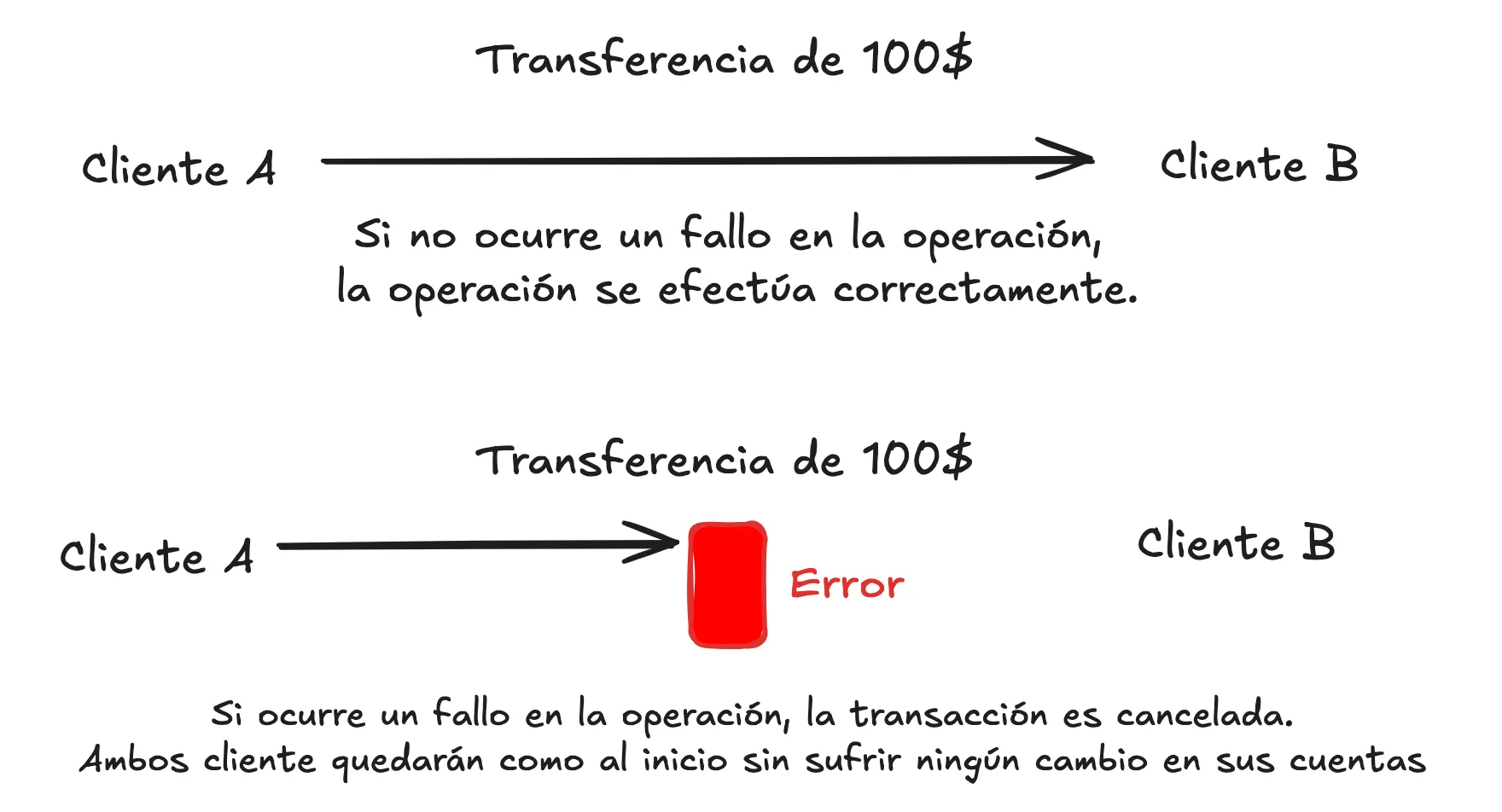
Una base de datos con tolerancia a particiones es capaz de efectuar las operaciones incluso si llegara a ocurrir un error en el sistema, pero si cumple esto, no logrará estar disponible siempre o será incosistente al momento de dar la información.
Implicaciones prácticas
Entender el teorema CAP es crucial para tomar decisiones informadas sobre el diseño de arquitecturas de bases de datos distribuidas y para comprender las compensaciones inherentes en los sistemas distribuidos modernos. Como regla general: si la precisión es crítica (como en bancos), se prioriza la consistencia; si la velocidad es clave (como en redes sociales), se prioriza la disponibilidad.
SQL
SQL (Structured Query Language) es un lenguaje de consultas diseñado para gestionar, manipular y consultar bases de datos relacionales (RDBMS). Desarrollado inicialmente por IBM en los años 70, basado en el modelo relacional de Edgar F. Codd, fue estandarizado por ANSI/ISO en 1986, consolidándose como el lenguaje universal para bases de datos.
¿Qué permite hacer SQL? SQL ofrece capacidades integrales para interactuar con datos, incluyendo:
- Definición de estructuras: Crear, modificar o eliminar tablas y esquemas.
- Manipulación de datos: Insertar, actualizar o eliminar registros.
- Consulta de información: Recuperar datos específicos con filtros avanzados.
- Control de acceso: Gestionar permisos y seguridad.
- Transacciones: Asegurar la integridad con operaciones atómicas.
SQL es un lenguaje cuya sintaxis se asemeja mucho al lenguaje natural, facilitando su aprendizaje e interpretación. A continuación, tenemos un ejemplo de una sentencia SQL:
SELECT ALL FROM usuarios;Si conocemos el significado de los términos en inglés, en la sentencia de arriba podemos interpretar que estamos seleccionando todos los datos de la tabla “usuarios” sin necesidad de conocer de base de datos.
Y efectivamente, si ejecuto esa sentencia, esta me devolverá todos los registros de la tabla “usuarios”.
SQL es un lenguaje que se basa en comandos, cada comando hace que PostgreSQL tome una acción concreta. Por ejemplo, el comando SELECT de arriba es un comando que selecciona datos de una tabla y lo usaremos siempre que queramos leer registros.
Grupos de comandos
Los comandos en SQL se pueden agrupar en diferentes categorías según su función principal:
| Grupo de Comandos | Descripción | Ejemplos de Comandos |
|---|---|---|
| DDL (Data Definition Language) | Se utilizan para definir y modificar la estructura de la base de datos | CREATE, ALTER, DROP, TRUNCATE, RENAME |
| DML (Data Manipulation Language) | Permiten manipular los datos dentro de las tablas | SELECT, INSERT, UPDATE, DELETE, MERGE |
| DCL (Data Control Language) | Gestionan los permisos y el control de acceso a los datos | GRANT, REVOKE |
| TCL (Transaction Control Language) | Controlan las transacciones en la base de datos | COMMIT, ROLLBACK, SAVEPOINT |
| DQL (Data Query Language) | Se utiliza específicamente para realizar consultas a la base de datos | Principalmente SELECT |
Cada uno de estos grupos de comandos cumple una función específica en el manejo de bases de datos relacionales. A lo largo del curso, aprenderás a utilizar cada uno de ellos de manera efectiva en PostgreSQL.
Nota: El grupo de comandos DQL (Data Query Language) es un grupo de comandos que no en todos los libros o tutoriales se menciona, porque lo incluyen directamente junto al DML. En nuestro caso, sí haremos uso de esta distinción para separar más el contenido.
En la imagen siguiente podemos ver los comandos de cada grupo:
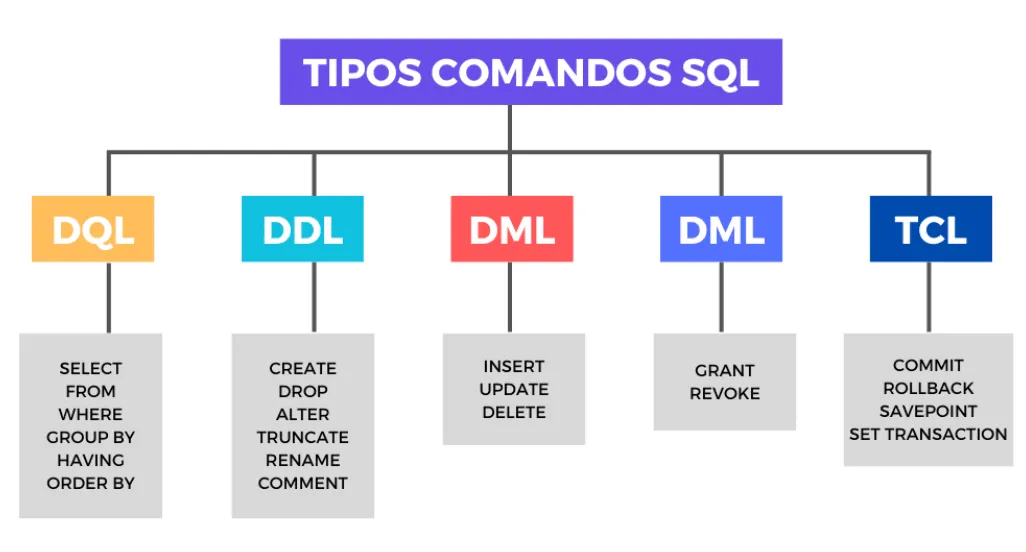
No hace falta que estudies por ahora estos comandos, ya que luego veremos clases en donde abordaremos cada uno de ellos hasta llegar al grupo de comandos TCL, para el contenido avanzado.
Enfoque de Este Curso: PostgreSQL
A lo largo de este curso, nos centraremos en PostgreSQL, un sistema de gestión de bases de datos relacional de código abierto que ha evolucionado a lo largo de más de 30 años de desarrollo activo. PostgreSQL ha ganado popularidad por su solidez, confiabilidad y por ser una de las bases de datos más avanzadas de código abierto disponibles actualmente.
PostgreSQL es compatible con la mayoría de los sistemas operativos (Linux, Windows, macOS) y se integra con prácticamente cualquier lenguaje de programación moderno. Su ecosistema incluye herramientas de administración gráfica como pgAdmin, DBeaver y TablePlus.
Exploraremos en profundidad estas características y aprenderás a aprovechar todo el potencial de PostgreSQL en aplicaciones del mundo real.
